데이터 인텔리전스 플랫폼으로 데이터 관리 혁신
데이터브릭스는 데이터 레이크하우스를 가장 강조하는 업체 중 하나다. 데이터브릭스는 오픈소스 빅데이터 플랫폼 생태계에서 빼놓을 수 없는 아파치 스파크(Apache Spark)의 창시자가 창업한 기업으로, 데이터 레이크하우스 플랫폼으로 세계 7,000개 이상의 고객을 보유하고 있다. 국내에는 2022년 4월 지사를 설립했다.

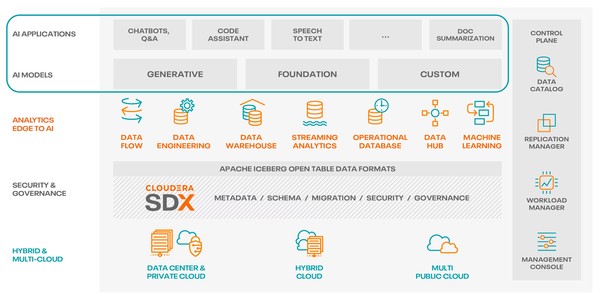
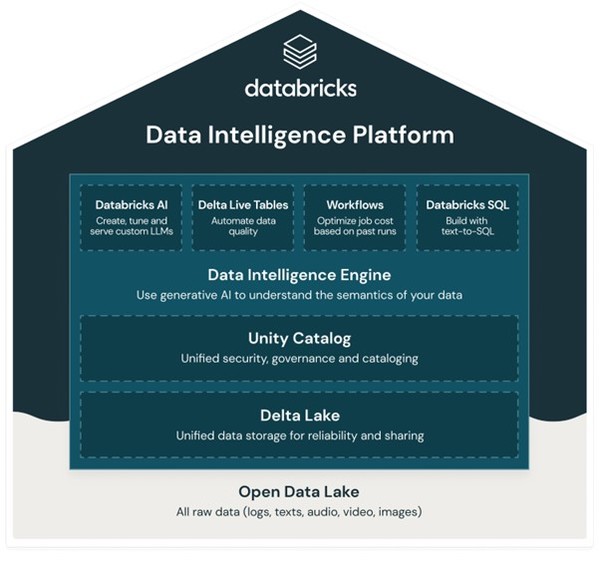
데이터브릭스는 현재 비즈니스 전면에 ‘데이터 인텔리전스 플랫폼(Data Intelligence Platform)’을 내세우고 있다. 데이터 인텔리전스 플랫폼은 AI 모델을 사용해 엔터프라이즈 데이터의 시맨틱(Semantics)을 심층적으로 이해함으로써 데이터 관리를 혁신한다. 데이터 인텔리전스 플랫폼은 기업의 모든 데이터를 쿼리하고 관리하는 통합 시스템인 레이크하우스를 기반으로 구축되지만, 데이터(콘텐츠 및 메타데이터)와 데이터 사용 방식(쿼리, 보고서, 계보 등)을 자동으로 분석해 필요에 따라 새로운 기능을 추가할 수 있다.


‘데이터 플랫폼’ 강조, 생성형 AI에 투자 확대
노우플레이크 역시 데이터 레이크하우스 시장의 대표 주자다. 오라클 출신의 데이터 전문가들이 모여 공동 창업했으며, 지난 2020년 미국 뉴욕증권거래소(NYSE)에 상장하는 과정에서 워렌 버핏이 공모주 투자에 나서면서 유명세를 얻었다. 국내에는 2021년 11월 지사를 설립했다.
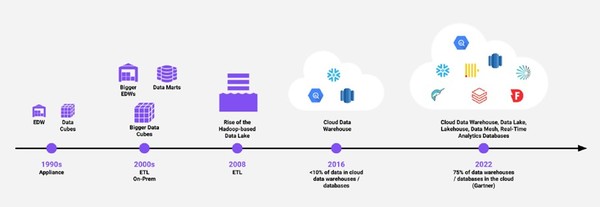
스노우플레이크는 SQL을 중심으로 하는 클라우드 데이터 웨어하우스에서 시작했다. 데이터 웨어하우스 기업이니만큼 기존에 구축된 데이터 레이크에 데이터 레이크하우스를 추가하는 것이 아니라, 데이터 웨어하우스를 기반으로 데이터 레이크로 확장하는 것을 의미한다.
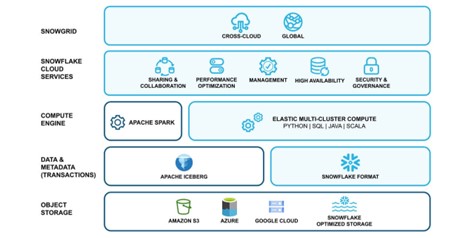
데이터 레이크를 기반으로 하는 데이터브릭스와의 방법과는 다소 차이가 있지만, 기업 내 모든 데이터에 접근 가능하면서 데이터 웨어하우스의 강력한 기능들을 활용할 수 있다는 장점이 있다. 스노우플레이크는 데이터 레이크하우스라는 용어보다는 클라우드 데이터 플랫폼(Cloud Data Platform)이라는 용어를 강조하고 있다.
스노우플레이크의 CDP 솔루션은 크게 △사용 용이성 △비용 효율성 △연결된 그리드 기능 △세분화된 거버넌스 등 4가지 장점을 갖고 있다. 먼저 사용 용이성이다. 스노우플레이크의 CDP는 플랫폼 구축, 업그레이드, 스토리지 유지 관리, 실행 엔진 프로비저닝와 같은 다양한 관리 작업이 자동화된 서비스로 제공되는 완전 관리형 서비스다. 이용자는 사용만 하고 관리를 스노우플레이크 측에 맡길 수 있다.
다음은 높은 성능과 비용 효율성이다. 파이썬, SQL, 자바, 스칼라를 사용해 정형, 반정형 및 비정형 데이터를 대규모 데이터 볼륨으로 처리가 가능하며, 동시에 다중 사용자의 요청을 성능 저하 없이 지원한다. 내장된 성능 최적화 기능을 통해 지속적으로 성능 개선 및 비용 최적화를 제공하고 있다.
세 번째는 전 세계에 연결된 그리드 기능을 갖고 있다는 점이다. 실행 환경이 AWS, MS 애저, GCP 등 어떤 CSP라도 하나의 일관된 사용자 경험을 제공한다. 멀티-클라우드 및 크로스-클라우드 환경에서 안전하게 데이터를 연결해 비즈니스 사일로 현상을 제거할 수 있으며, 새로운 비즈니스 모델을 만들 수 있다.
마지막은 세분화된 거버넌스를 지정할 수 있다는 점이다. 데이터 민감도, 사용량, 관계를 전체적으로 이해하고 세분화된 접근 제어 정책을 통해 데이터를 보호할 수 있다.
구체적으로 데이터 분류 체계를 통해 민감한 데이터와 PII 데이터를 감지하고 식별할 수 있고, 객체 태그를 지정해 규정 준수, 검색, 보호 및 리소스 사용에 대한 민감한 데이터를 모니터링할 수 있다. 또한 다이나믹 데이터 마스킹 정책을 통해 데이터를 안전하게 보호할 수 있으며 태그 기반 마스킹 정책을 통해 데이터를 안전하게 보호할 수 있다.


개방형 데이터 레이크하우스 ‘클라우데라 데이터 플랫폼’ 제공
아파치 하둡과 아파치 스파크 기반 SW를 지원하는 서비스를 제공하는 미국 기업인 클라우데라 역시 데이터 레이크하우스 시장에서 주목받는 기업 중 하나다. 현재 클라우데라는 하이퍼스케일러와 동일하게 고객의 25엑사바이트 규모의 데이터를 관리하고 있다. 클라우데라의 데이터 레이크하우스 핵심 전략은 기업이 안전하고 신뢰할 수 있는 AI를 이용할 수 있도록 개방형 데이터 레이크하우스인 ‘클라우데라 데이터 플랫폼(Cloudera Data Platform)’을 제공하는 것이다.